
Video · Main view
待上传 · 主视角 / 第三人称
VLM/VLA visual grounding
- Pinhole projection
- Global spatial cues
✅ Matches VLM/VLA pretraining
1Institute of Artificial Intelligence (TeleAI), China Telecom ·
2Lumos Robotics
3University of Science and Technology of China ·
4Northwestern Polytechnical University
5Shanghai Jiao Tong University ·
6East China University of Science and Technology
7Harbin Engineering University ·
8Fudan University
† Equal contribution · ‡ Project lead · * Corresponding authors
Universal Manipulation Interface (UMI) enables scalable real-world robot data collection without hardware-specific teleoperation, yet leveraging UMI data to train large-scale Vision-Language-Action (VLA) models remains fundamentally challenging. We identify two critical mismatches: wrist-mounted fisheye views, with severe radial distortion and local gripper-centric perspectives, are out-of-distribution for pretrained VLMs; and human-collected trajectories frequently violate kinematic limits, incur collisions, or exceed controller bandwidth, teaching VLA policies physically infeasible actions. To address the challenges, we present VISTA, a framework that bridges this dual gap through three synergistic components. (i) UMI-VQA, the first large-scale VQA dataset tailored to wrist-mounted fisheye observations, aligns VLM representations to the distorted visual regime via auxiliary vision-language supervision. (ii) A systematic physical-validation pipeline performs a data-completeness pre-check and scores each valid trajectory for trajectory continuity, self-collision risk, and execution fidelity before it enters training. (iii) A two-stage co-training recipe jointly learns vision-language grounding on UMI-VQA and action prediction on validated trajectories. Our experiments empirically show that incorporating UMI-VQA consistently improves downstream policy performance, and that physical-validation scores are strongly predictive of deployment success. On diverse simulation and real-world manipulation tasks, VISTA significantly outperforms strong baselines including \( \pi_{0.5} \), LingBot-VLA, and Wall-X. We release the physical-validation pipeline, UMI-VQA, validated trajectory data, and the pre-trained model for the community.
Standard VLA and VLM pipelines are built on relatively global, pinhole-perspective supervision. UMI instead records wrist-mounted fisheye views that are local, gripper-centric, and visually far from this pretraining regime.
待上传 · 主视角 / 第三人称
VLM/VLA visual grounding
✅ Matches VLM/VLA pretraining
待上传 · 手腕鱼眼 · 155° FOV
Fisheye view in UMI
❌ Out-of-distribution for standard VLMs/VLAs
Perception degradation under fisheye observations
Raw human demonstrations inherently lack awareness of target robot constraints, such as joint limits, workspace boundaries, and self-collision risks. Training VLA models on this unconstrained data causes the robot to learn physically infeasible actions, inevitably leading to systematic deployment failures.
To visually demonstrate this issue, we analyzed the execution of three representative tasks. Unconstrained trajectories often suffer from severe tracking errors. The curves below compare the position and orientation deviations between successful and failed trajectories, showing exactly how these physical limits disrupt the task.
To address the inherent mismatches of raw UMI data, we propose VISTA, a UMI-oriented VLA framework comprising UMI-VQA for perceptual alignment, a systematic trajectory-level physical validation pipeline for embodiment-aware data curation, and a two-stage co-training recipe with a flow-matching action expert.
Perceptual alignment. We first tackle the visual domain gap by introducing an 8M-sample UMI-VQA dataset, adapting the model to wrist-mounted fisheye observations.
Physical validation. Next, we enforce physical plausibility with a data-completeness pre-check and trajectory scoring for continuity, self-collision risk, and execution fidelity, filtering out unexecutable human motions.
Two-stage co-training. Finally, we employ a two-stage training recipe: an initial VQA-Action co-training phase for representation alignment, followed by a flow-matching action expert for continuous control.
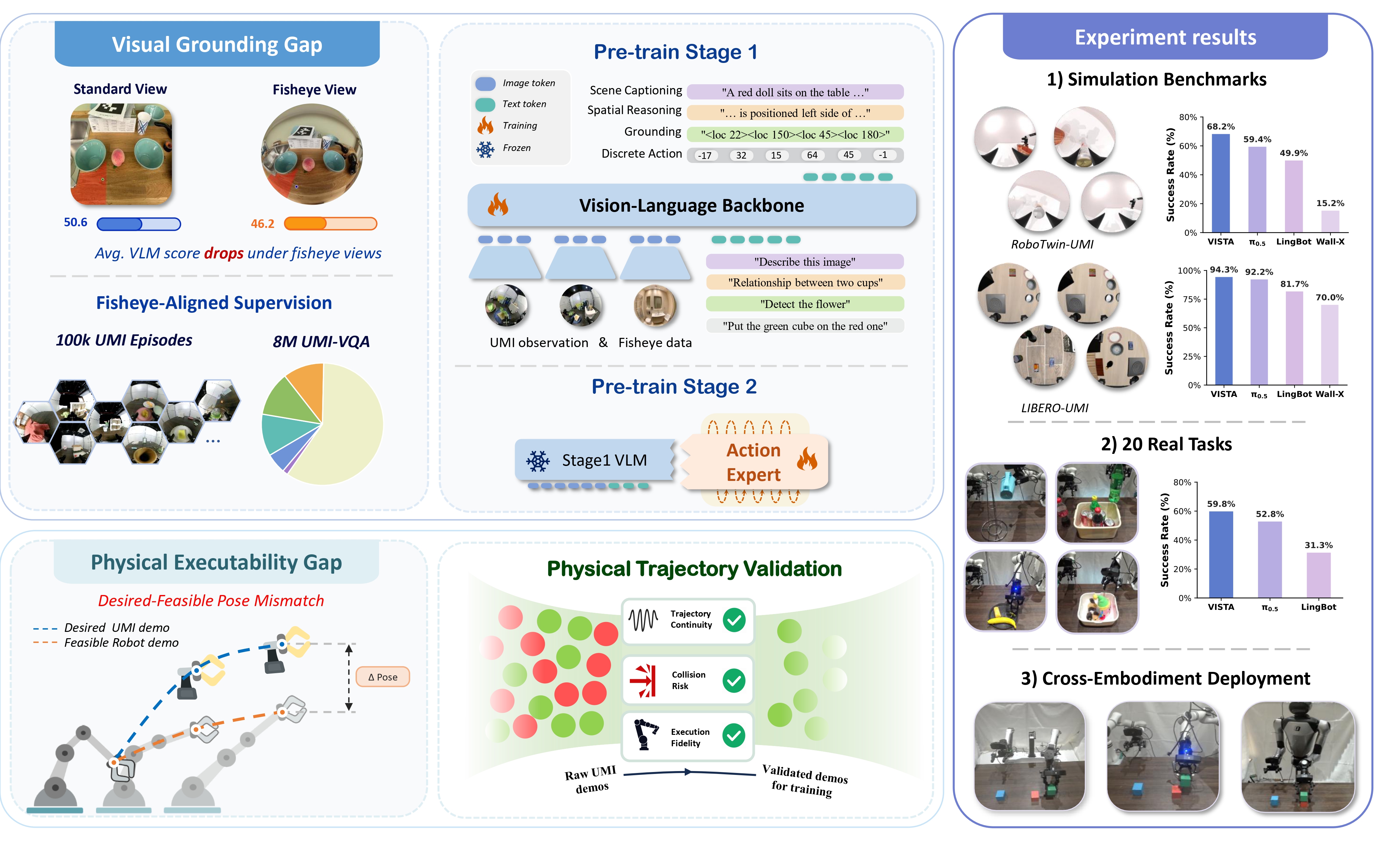
We construct the UMI-VQA Dataset to resolve the visual-grounding mismatch inherent in fisheye observations. This large-scale dataset contains 8M vision-language samples built from authentic real-world UMI demonstration frames and edited spatial-diversity images.
The dataset is structured into five capability-oriented subsets designed to systematically supervise the perceptual abilities required for wrist-fisheye manipulation:
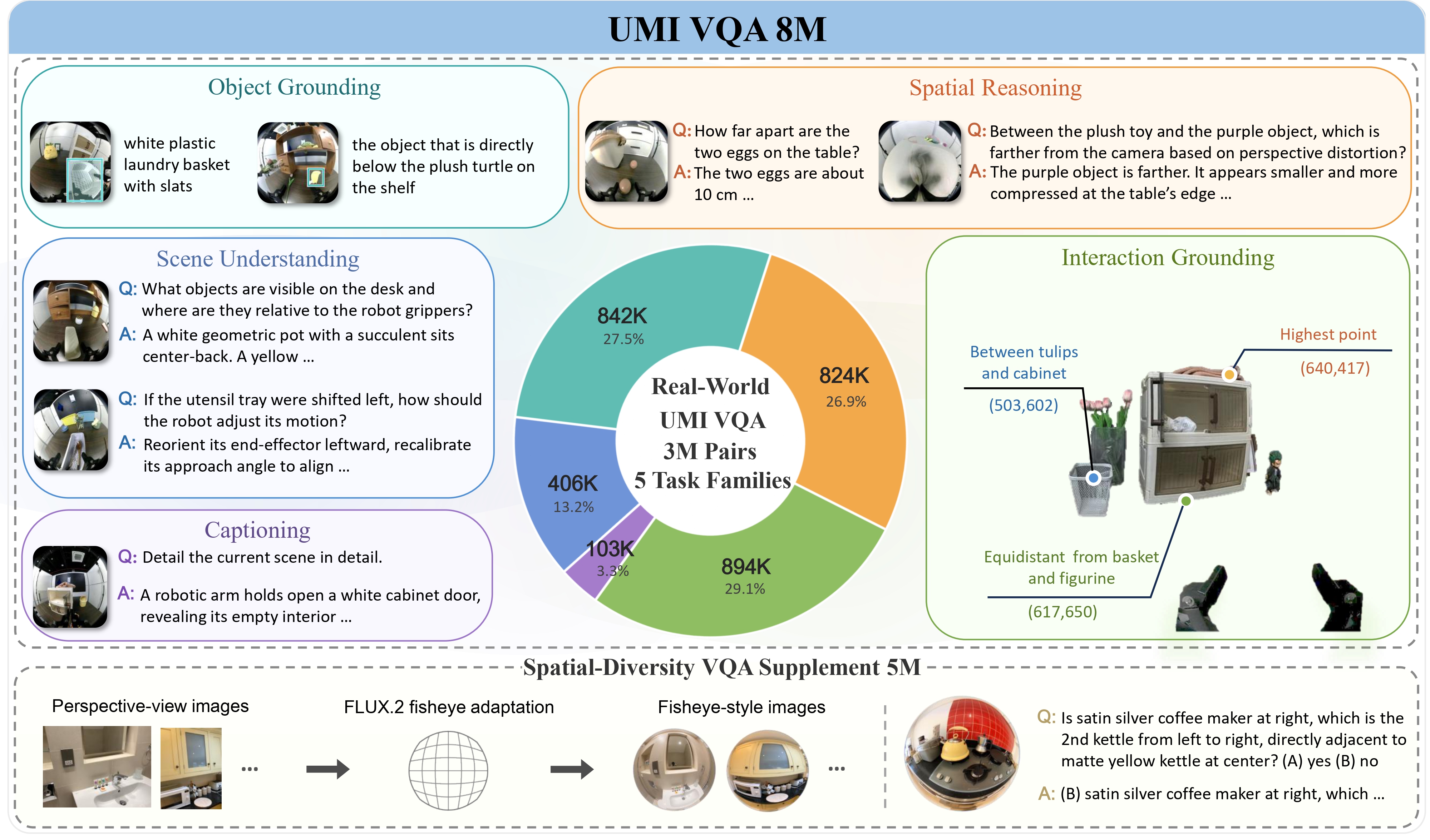
Before training, each trajectory is replayed in a cross-embodiment MuJoCo + Mink pipeline (RealMan, AC one, R1 Pro), scored along three complementary axes plus a data-completeness pre-check, and aggregated into an overall cross-embodiment score \(S(\tau, e)\) via a weighted geometric mean. Trajectories below the validation threshold are filtered out.
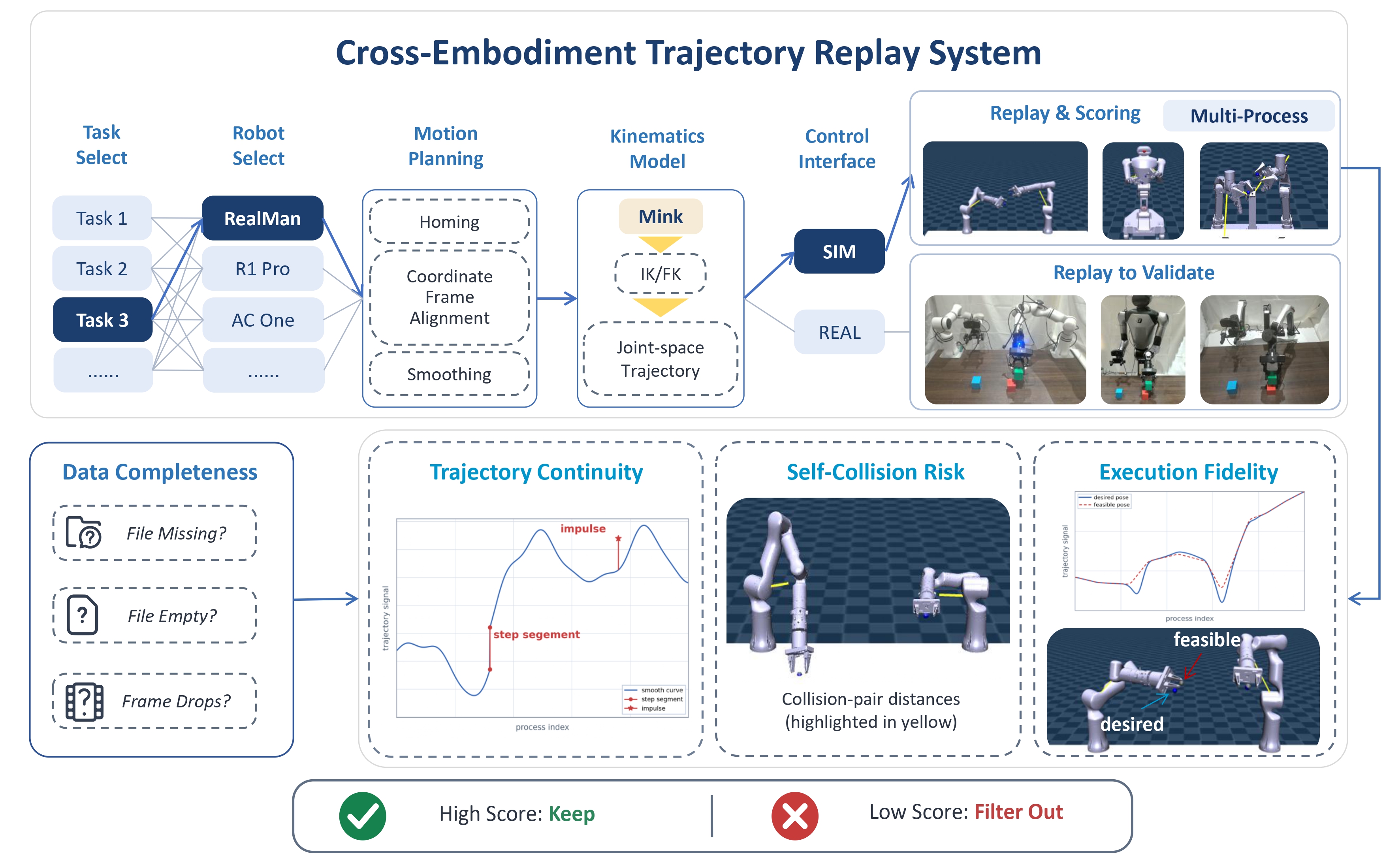
VISTA is pre-trained on large-scale perception-aligned corpora comprising 8M UMI-VQA samples and 100K real-world robot trajectories. Pre-training proceeds in two stages: autoregressive co-training on VQA and discretized actions to align the VLM backbone with the fisheye observation regime, followed by continuous-action refinement via a knowledge-isolated flow-matching expert.
We first co-train the VLA backbone on action prediction and VQA answering under a unified autoregressive objective.
To prevent catastrophic forgetting of the perception and discrete-action knowledge acquired in Stage 1, we follow the knowledge-isolation strategy, keeping the pretrained VLA backbone frozen and training a separate continuous action expert on top.
After pre-training, VISTA is adapted to downstream tasks and target embodiments. We first apply a strict physical validation threshold to filter downstream task data for the specific deployment robot, removing trajectories with kinematic violations, self-collision risks, or poor replay fidelity.
During fine-tuning, we unfreeze the full model and update both the VLA backbone and the flow-matching action expert end-to-end—preserving generalist visual-linguistic knowledge while specializing perception and continuous action generation to the target robot’s dynamics and task distribution.
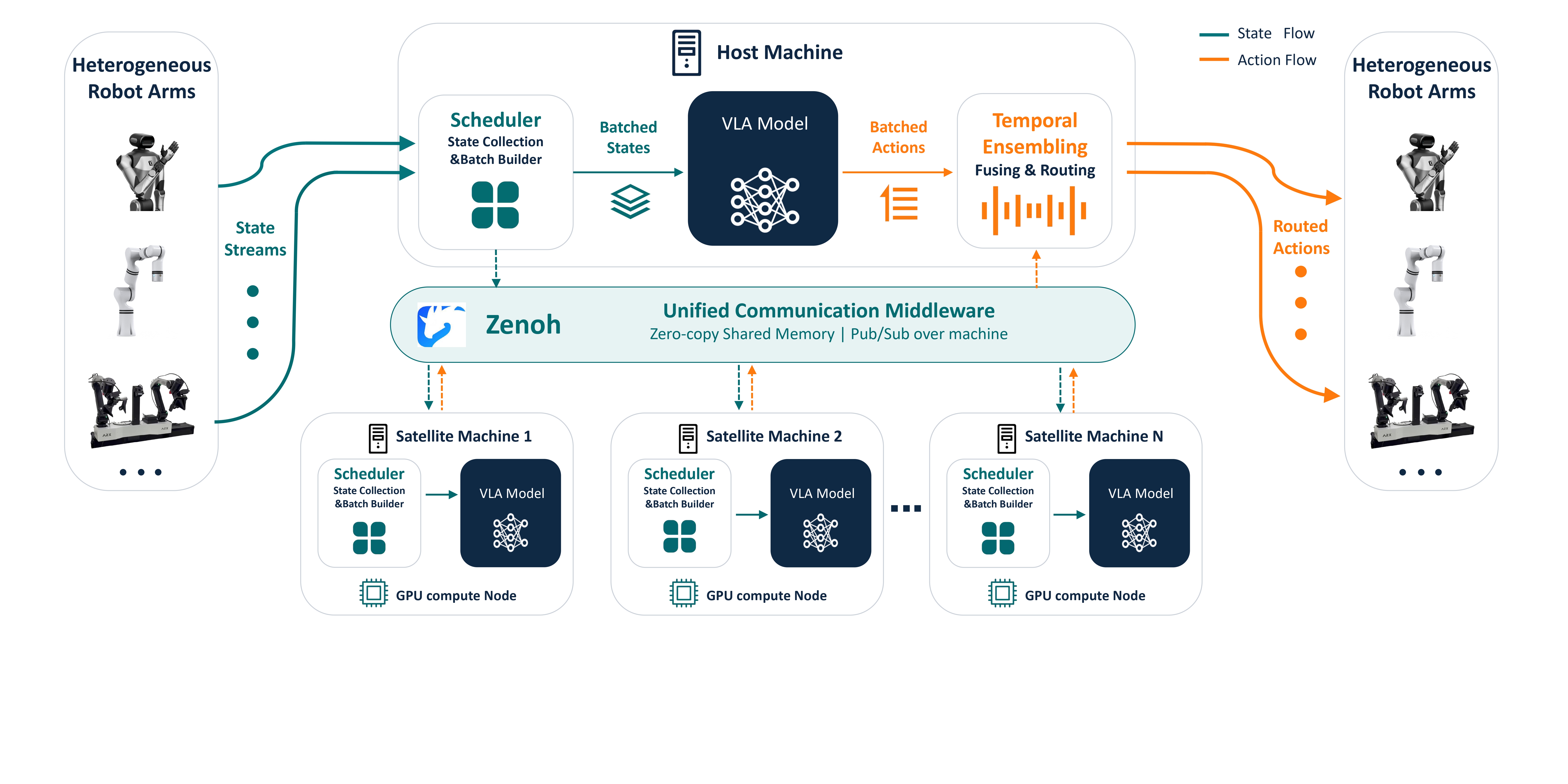
To fully exploit the cross-embodiment potential of VISTA, we implement a pure Python distributed deployment architecture for heterogeneous robotic arms. The system uses Zenoh as the communication middleware, enabling transparent shared-memory or network-level transmission across local processes, LANs, or WANs. State streams from multiple arms are aggregated to distributed GPU compute nodes for batched inference; predicted action chunks are temporally ensembled and routed back to the respective robots via synchronous RPC calls to ensure strict temporal alignment and prevent command accumulation. This design eliminates heavy ROS dependencies and allows seamless integration of new robot arms that satisfy the UMI end-effector mounting specification.
Diagnostic validation aims to verify the two UMI-to-VLA bottlenecks: perception mismatch and physical infeasibility. We evaluate these challenges by measuring policy degradation under wrist-fisheye views on the LIBERO and RoboTwin benchmarks, assessing the impaired visual reasoning of VLMs across four spatial benchmarks (Where2Place, RefSpatial, ERQA, EmbSpatial), and demonstrating the physical unexecutability of raw human trajectories via real-robot replay on the RealMan embodiment.
We evaluate the impact of UMI-style observations on policy learning. Table 1 confirms this genuine perception bottleneck across multiple VLA models (\( \pi_{0.5} \), LingBot-VLA, WALL-X) and benchmarks (LIBERO, RoboTwin), demonstrating consistent performance degradation under wrist-fisheye training.
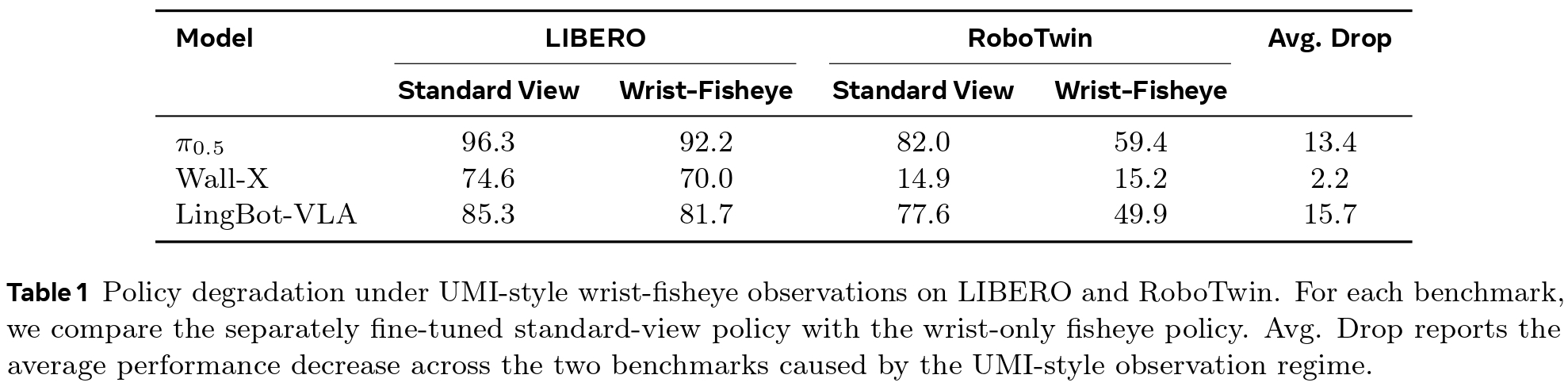
To quantify visual reasoning degradation, we evaluate five general and robot-specialized VLMs across four spatial benchmarks. As shown in Table 2, fisheye-transformed images cause a consistent performance drop across all models (averaging an 8.6% relative degradation) compared to standard perspectives. This confirms that pretrained VLMs lose critical spatial and object understanding under distorted wrist-fisheye views, necessitating our perception-aligned VQA.
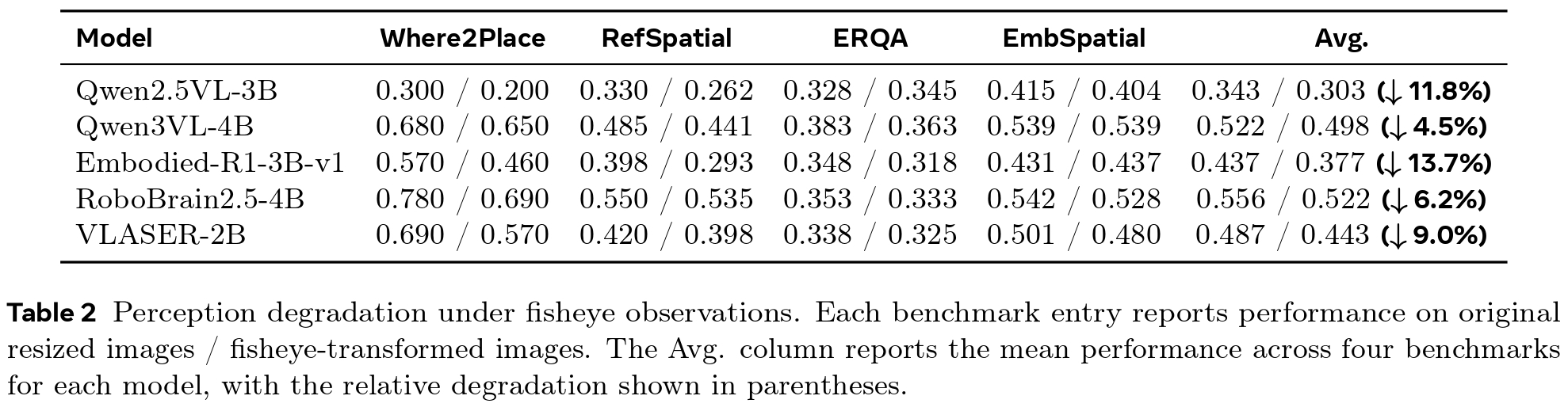
We audit the physical executability of raw UMI trajectories on a RealMan robot across three representative tasks. As illustrated in Figure 6, both simulation and real-world replays reveal significant deviations between human-demonstrated trajectories and feasible robot poses due to inherent physical constraints. These execution deviations directly cause task failures, empirically confirming that human-collected UMI data cannot serve as executable supervision without physical validation, otherwise VLA models will learn physically infeasible actions.
In this section, we evaluate whether the two data-level components of VISTA effectively address the two UMI-to-VLA bottlenecks identified in the diagnostic validation.
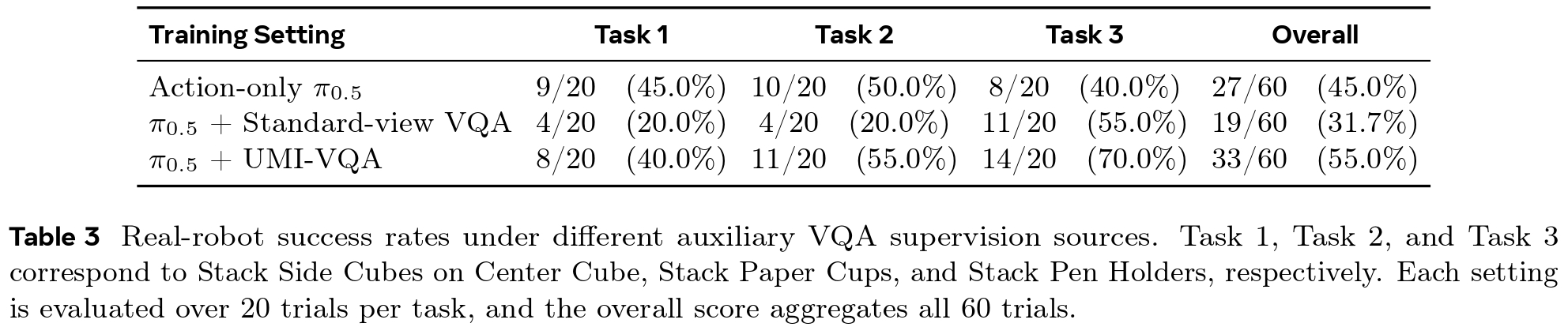
We demonstrate that co-training with wrist-fisheye-aligned UMI-VQA significantly improves policy performance, increasing the aggregate success rate from 45.0% to 55.0%. Conversely, using standard-perspective VQA degrades performance due to a severe visual distribution mismatch.
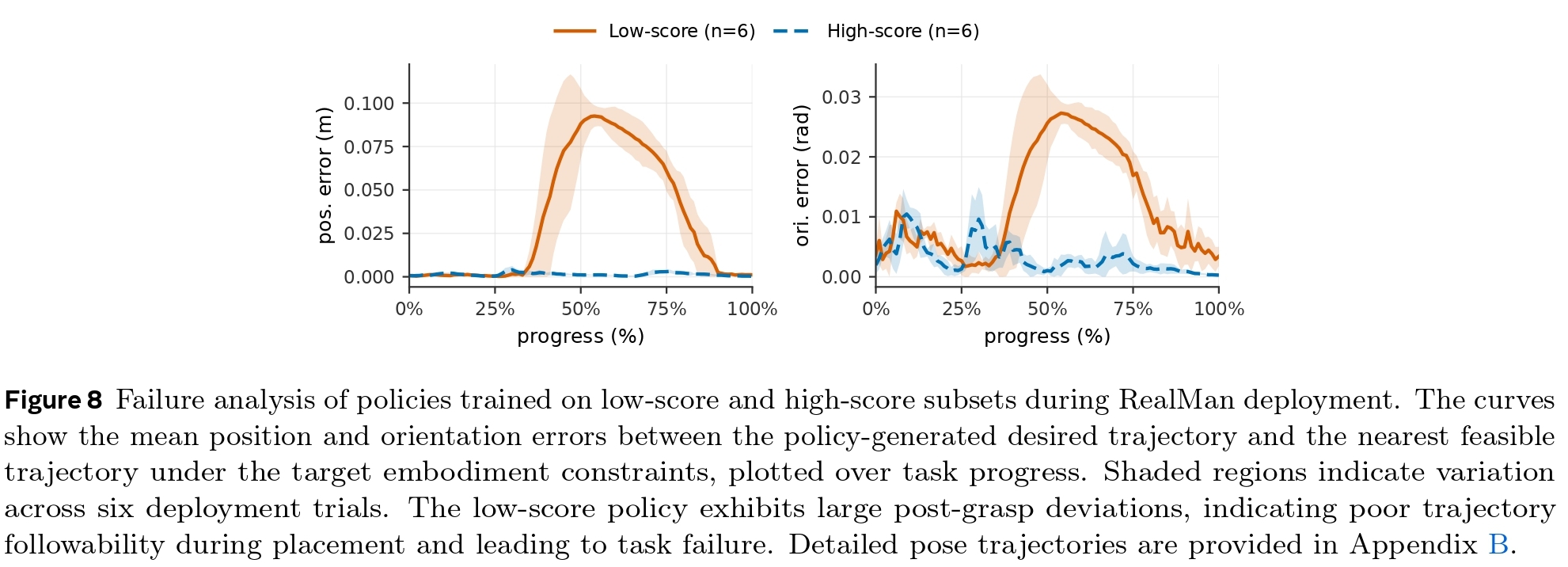
We evaluate whether physical scoring effectively prevents the policy from learning unexecutable actions. Using a stapler-placement task on a RealMan robot, we compared policies trained on two equally-sized data subsets: one with low physical scores and one with high physical scores.
We measured three metrics: Grasping Success Rate (GSR), Overall Success Rate (OSR), and Post-grasp Success Rate. While both policies achieved comparable GSR, the high-score policy dramatically outperformed the low-score policy in both PSR and OSR.

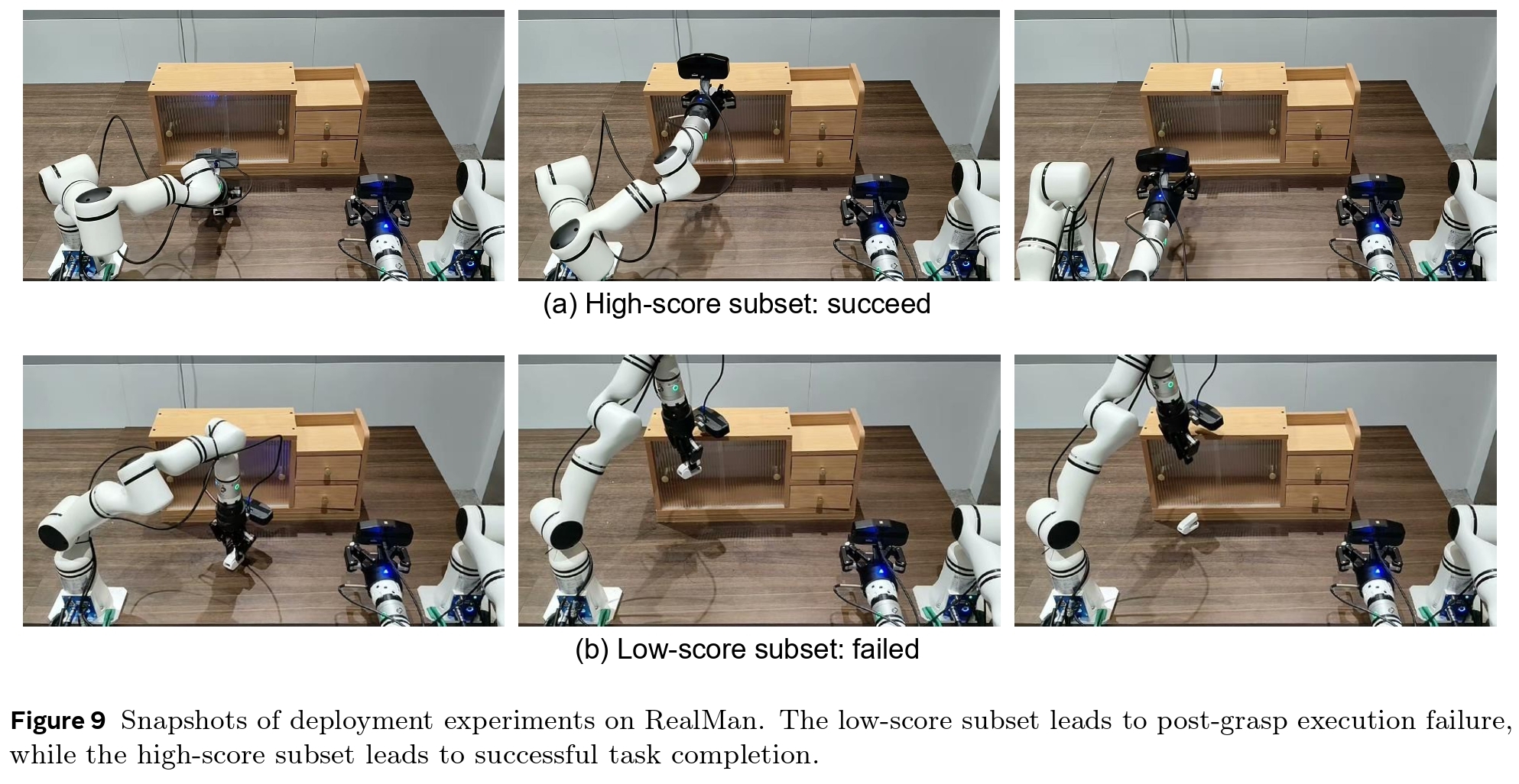
An inspection of real-world deployments reveals that policies trained on low-score data generate trajectories that exceed the target robot's workspace limits, causing critical execution deviations. High-score data produces highly executable motions that the robot can faithfully follow.
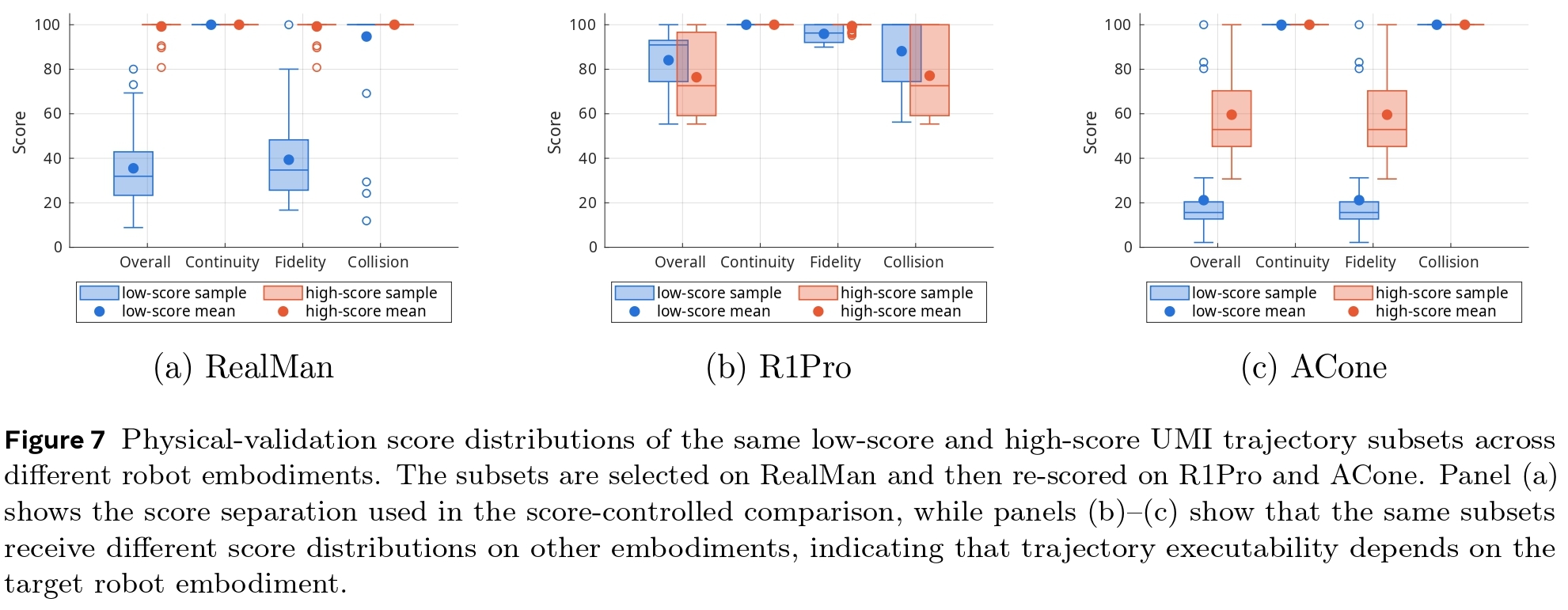
We re-score identical UMI trajectories across different robotic platforms (RealMan, R1Pro, ACone) and show that a trajectory's feasibility varies by embodiment. This highlights that trajectory filtering must be explicitly conditioned on the target robot to ensure reliable deployment.

We evaluate VISTA against three VLA baselines (\( \pi_{0.5} \), LingBot-VLA, and WALL-X) on two adapted UMI-style simulation benchmarks: RoboTwin-UMI and LIBERO-UMI. To ensure a fair comparison that isolates our architectural adaptations, all models are trained on the exact same recollected wrist-fisheye demonstrations. VISTA achieves the highest performance across both benchmarks, reaching an average success rate of 81.3%. This outperforms \( \pi_{0.5} \) by 5.5 points, LingBot-VLA by 15.5 points, and WALL-X by 38.7 points, demonstrating that explicit adaptation to fisheye observations and validated action data significantly enhances policy learning.

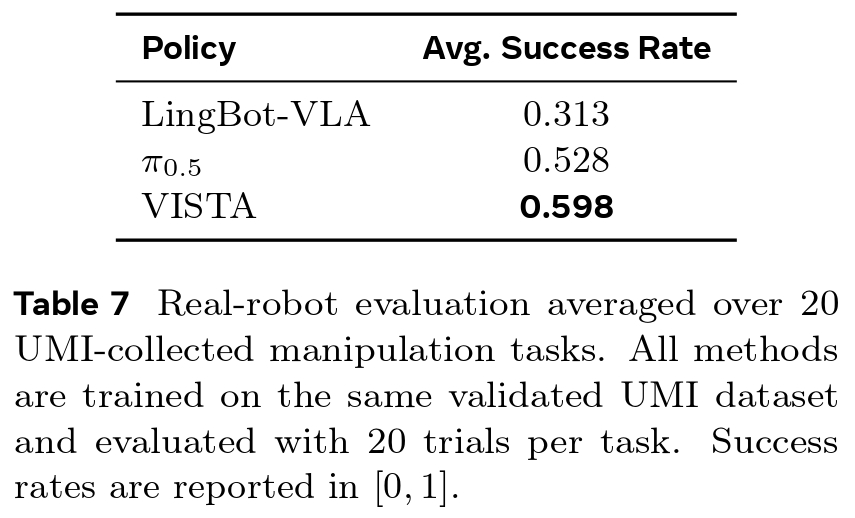
We deploy VISTA across 20 diverse real-world UMI-collected manipulation tasks that test complex capabilities like precise spatial localization and dual wrist-view integration. All methods are evaluated under strictly controlled conditions, utilizing the same validated UMI dataset, robot platform, and object configurations across 20 trials per task. VISTA achieves the highest average success rate of 59.8%, delivering a 7.0-point absolute gain over \( \pi_{0.5} \) and outperforming LingBot-VLA by 28.5 points. These results prove that the benefits of VISTA's UMI-oriented design successfully transfer to robust, physical robot deployment.
Close Laptop and Place Mouse
Place Dolls into Box
Take Dolls out of Box
Place Stapler on Cabinet
Stack Side Cubes on Center Cube
Sort Cubes by Color into Tray
Retrieve Toast from Toaster
Pick Target Fruits from Bowl
Put Doll into Drawer and Close
Open Drawer
Organize Dolls
Place Bun into Rice Cooker and Close
Arrange Flowers
Place Drink into Box
Hang Mug on Rack
Stack Pen Holders
Pour Chips from Bowl to Plate
Pick Plum from Cluttered Fruits
Stack Paper Cups
Place Fruits
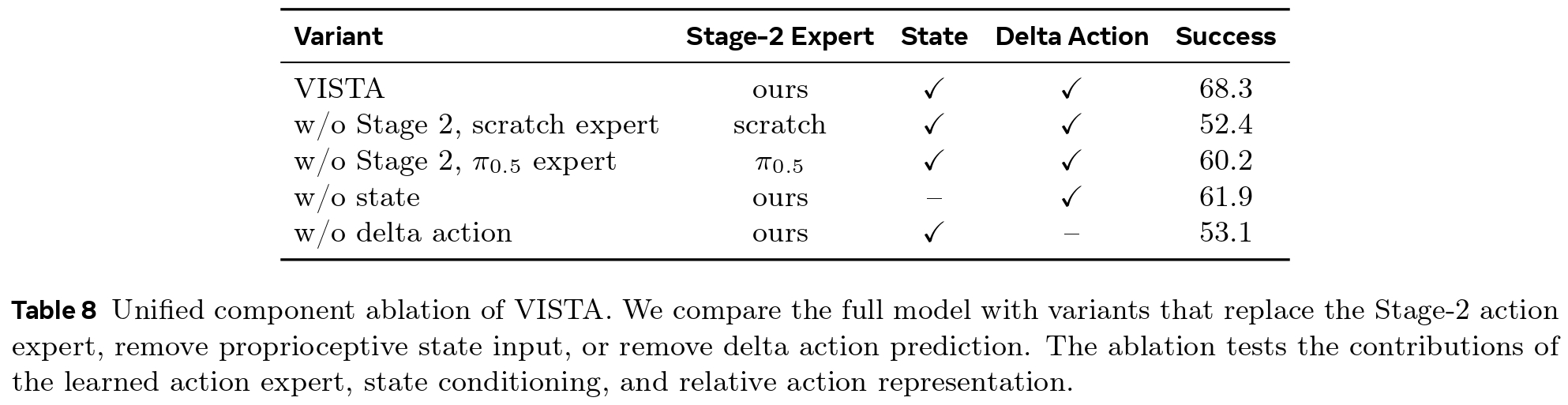
We conduct a unified ablation study to isolate the impact of VISTA's key architectural designs. Compared to the full model's 68.3% success rate, performance drops significantly when replacing the Stage-2 flow-matching action expert (down to 52.4% from scratch, or 60.2% using the original \( \pi_{0.5} \) expert), removing proprioceptive state inputs (down to 61.9%), or switching from delta to absolute action prediction (down to 53.1%). This validates the critical contributions of our two-stage action expert, state conditioning, and relative action representations.
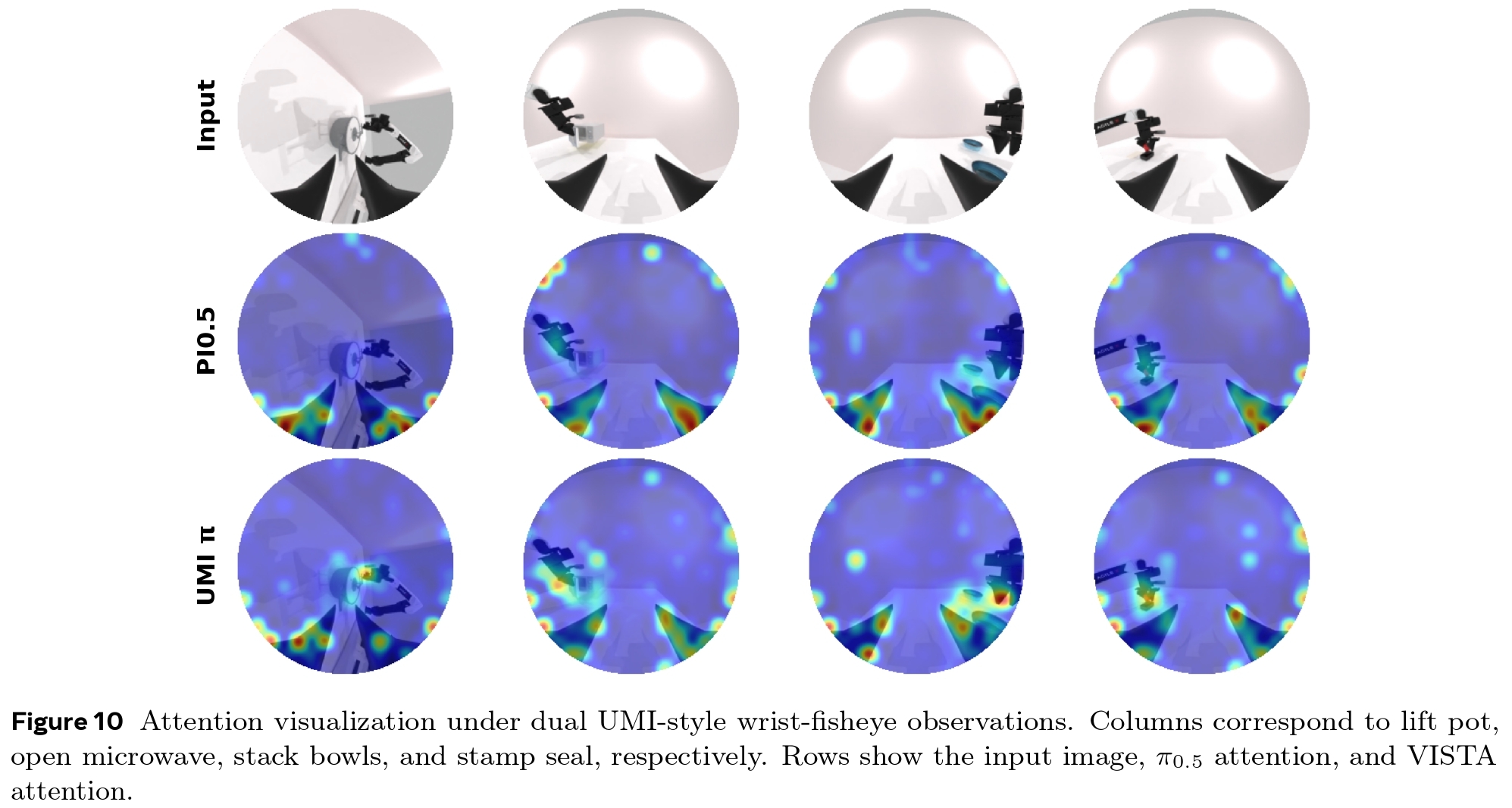
To qualitatively assess visual grounding, we visualize the attention maps of both VISTA and \( \pi_{0.5} \) processing auxiliary wrist-fisheye views. While \( \pi_{0.5} \) exhibits diffuse and scattered attention, VISTA successfully localizes its focus on critical task-relevant areas, including the active gripper, the manipulated object, and the local interaction region. This confirms that VISTA develops a much stronger and more precise visual understanding of UMI-style observations.
8M wrist-fisheye vision-language samples across five capability subsets.
5k real-world UMI demos scored and filtered via cross-embodiment Mink replay.
Pre-trained VISTA checkpoints.
Two adapted UMI-style simulation benchmarks, physical-validation pipeline, two-stage training recipe.
@article{yang2026vista,
title = {VISTA: Vision-Grounded and Physics-Validated Adaptation of UMI data for VLA Training},
author = {Siyuan Yang and Linzheng Guo and Ouyang Lu and Zhaxizhuoma and Daoran Zhang and Xinmiao Wang and Ting Xiao and Fangzheng Yan and Zhijun Chen and Yan Ding and Chao Yu and Chenjia Bai and Xuelong Li},
journal = {arXiv preprint arXiv:2606.04708},
year = {2026},
}